 [웹크롤링] 'title', 'src', 'href' 속성에 있는 텍스트 크롤링하기
웹 크롤링을 하다 보면, 'title', 'src', 'href' 속성에 있는 텍스트 또는 url을 크롤링해야 할 수 있는데요, 태그 이름 또는 클래스 이름으로 찾는 방법은 쉽지만 title, src, href과 같은 속성으로 텍스트를 추출하는 방법을 잘 모를 수 있습니다. 따라서 코드를 살펴보면서 크롤링하는 방법에 대해서 알아볼건데요, 예시로 아래 이미지처럼 네이버 뉴스 기사에서 '서울경제'라는 이미지가 있는 태그에서 '서울경제'라는 텍스트를 추출해보겠습니다. 오른쪽 태그를 더 자세히 보면, 라는 상위 태그 아래 태그에 'title'속성에 '서울경제'라는 텍스트가 적혀있는 것을 확인할 수 있습니다. 이제 이 텍스트를 크롤링하는 코드에 대해서 살펴보도록 하겠습니다. url = https://news.na..
더보기
[웹크롤링] 'title', 'src', 'href' 속성에 있는 텍스트 크롤링하기
웹 크롤링을 하다 보면, 'title', 'src', 'href' 속성에 있는 텍스트 또는 url을 크롤링해야 할 수 있는데요, 태그 이름 또는 클래스 이름으로 찾는 방법은 쉽지만 title, src, href과 같은 속성으로 텍스트를 추출하는 방법을 잘 모를 수 있습니다. 따라서 코드를 살펴보면서 크롤링하는 방법에 대해서 알아볼건데요, 예시로 아래 이미지처럼 네이버 뉴스 기사에서 '서울경제'라는 이미지가 있는 태그에서 '서울경제'라는 텍스트를 추출해보겠습니다. 오른쪽 태그를 더 자세히 보면, 라는 상위 태그 아래 태그에 'title'속성에 '서울경제'라는 텍스트가 적혀있는 것을 확인할 수 있습니다. 이제 이 텍스트를 크롤링하는 코드에 대해서 살펴보도록 하겠습니다. url = https://news.na..
더보기
[웹크롤링] 크롤링해서 얻은 텍스트, 앞 뒤 공백 제거하려면? - strip
크롤링을 하면 주로 텍스트를 추출하게 되는데요, 이때 추출한 텍스트 앞, 뒤로 공백이 같이 추출될 수 있습니다. 이러한 경우 공백을 제거한 뒤 저장하는 것이 나중에 분석 및 처리를 위해서도 좋은데요, 어떻게 하면 앞, 뒤 공백을 제거할 수 있는지 살펴보도록 하겠습니다. - strip() : 문자열 앞 뒤 공백 제거하기 먼저, 다음과 같이 뉴스 기사 제목을 크롤링해서 저장한 리스트가 있다고 가정해보겠습니다. news = [' KBS \'절반 억대연봉\' 사과에…나경원 "수신료인상 반대" ', ' SK하이닉스 성과급 불만에 최태원 "작년 연봉 전부 반납" 선언', " 안철수-금태섭 채널 열렸다…野 '계단식 단일화론' 급물살(종합)" , '與, 법관탄핵안 161명 공동발의…4일 국회통과 유력(종합) ', ' ..
더보기
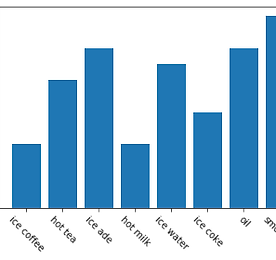 [데이터분석] matplotlib 그래프 : x축 텍스트 회전하는 방법 - rotation
matplotlib 라이브러리는 그래프를 쉽고 간편하게 그릴 수 있도록 도와주는 라이브러리입니다. matplotlib에서는 그래프를 다양하게 그릴 수 있도록 여러 모듈을 제공하는데요, 그중 x축 텍스트를 회전하는 방법에 대해서 살펴보도록 하겠습니다. 먼저, 아래와 같이 간단한 그래프를 그려보도록 하겠습니다. import matplotlib.pyplot as plt import numpy as np x = np.arange(8) item = ['ice coffee', 'hot tea', 'ice ade', 'hot milk', 'ice water', 'ice coke', 'oil', 'smoothie'] values = [2000, 4000, 5000, 2000, 4500, 3000, 5000, 6000]..
더보기
[데이터분석] matplotlib 그래프 : x축 텍스트 회전하는 방법 - rotation
matplotlib 라이브러리는 그래프를 쉽고 간편하게 그릴 수 있도록 도와주는 라이브러리입니다. matplotlib에서는 그래프를 다양하게 그릴 수 있도록 여러 모듈을 제공하는데요, 그중 x축 텍스트를 회전하는 방법에 대해서 살펴보도록 하겠습니다. 먼저, 아래와 같이 간단한 그래프를 그려보도록 하겠습니다. import matplotlib.pyplot as plt import numpy as np x = np.arange(8) item = ['ice coffee', 'hot tea', 'ice ade', 'hot milk', 'ice water', 'ice coke', 'oil', 'smoothie'] values = [2000, 4000, 5000, 2000, 4500, 3000, 5000, 6000]..
더보기




