에어 프로젝트
#5 Memory Networks (MemNN)로 뉴스 기사 QnA(질의응답) 예측 모델 만들기

위 이미지를 보면 BTS 관련 뉴스기사 본문과, 문제가 나와 있다. 2개의 문제 모두 본문을 읽고 나면 충분히 답할 수 있는 문제다. 그렇다면 만약 인공지능한테 이 본문을 보여주고 문제를 풀라고 하면 과연 정답을 맞힐 수 있을까? 아마 인공지능이 정답을 맞히려면 먼저 질문의 의도를 파악해야 하며, 기사 문맥의 흐름을 이해해야 할 것이다. 하지만 어떻게 인공지능 스스로 문맥의 정보를 학습할 수 있을까?
이에 대한 해결방법으로 기계번역 모델 중 '메모리 네트워크(Memory Networks)' 라는 신경망 있는데, 위와 같은 문제에 최적화된 알고리즘이다. 따라서 이번 에어 프로젝트에서는 이러한 메모리 네트워크에 대해 간단하게 알아보고, 메모리 네트워크를 이용하여 뉴스 기사 본문에 대한 질문에 답을 예측하는 모델을 만들어 보도록 하겠다!
|| 메모리 네트워크(Memory Networks)란?
메모리 네트워크는 2015년 발표된 논문 'MEMORY NETWORKS_Jason Weston, Sumit Chopra & Antoine Bordes'에서 소개된 신경망으로, 적은 memory를 가지고 있는 기존의 신경망의 문제를 해결하고자 등장한 신경망이다. 예를 들어, 긴 문장이 input으로 주어지고 다음 단어를 예측해야 할 때, 기존의 신경망은 memory가 작아 과거의 정보를 잘 이용하지 못하고, 과거의 정보를 잘 구분하지 못하곤 했다. 하지만 메모리 네트워크는 긴 문장에서 필요한 부분만 long-term memory component를 결합함으로써 다음 단어에 대해 효과적인 추론을 하도록 한다.
그렇다면 이러한 과정이 어떻게 이루어지는 것일까? 논문에 따르면, 메모리 네트워크는 메모리 m과 4개의 요소 I, G, O, R로 이루어져 있는데, 각 요소의 역할에 대해서 간단하게 알아보도록 하겠다.
먼저 I(input feature map)는 입력을 내부 feature representation I(x)로 바꾸어(embedding) 줌을 의미한다. 이 과정에서 parsing, coreference, entity resolution 등의 과정이 포함될 수 있고, raw 한 입력값을 feature vector로 만들게 된다.
두 번째로, G(generalization)는 새로운 입력을 통해 기존의 memory를 업데이트 하는 generalization을 의미한다. 간단한 형태는 memory를 slot에 저장하는 것인데, 업데이트를 할 때 기존에 slot에 저장된 memory를 제거하거나 부분적으로 제거한 후에 update를 한다. 또한 memory가 커질 땐 이를 조직화하는 과정을 거치게 된다.
세 번째로, O(output feature map)는 새로운 입력과 memory에 있는 값들을 토대로 output feature를 계산하게 된다. 즉, memory를 읽고 입력 문장에 대한 추론 과정을 수행하게 되는데, 연관성이 높은 memory와 연산해 output을 만들어낸다.
마지막으로 R(response)은 output feature을 원하는 포맷의 response로 디코딩해서 최종 output을 만드는 것인데, 이때 벡터를 다시 text로 만들어 내는 과정을 거치게 된다.
이렇게 메모리 네트워크의 주요 요소에 대해 알아보았는데, 각 요소에 대한 수식과 세부사항에 관해서는 논문을 참고하길 바란다.
|| Project Description
이번 에어 프로젝트는 Memory Networks를 이용하여, 뉴스 기사 내용과 관련된 질의에 대해 적절한 답변을 하는 예측 모델을 만들고자 한다. 프로젝트 모델을 만들기 위해 MemNN을 간단히 이용한 예제 코드를 참고했는데, 먼저 1) 참고한 코드를 어떻게 응용 및 변형해서 사용할 건지를 설명하고, 2) 학습에 사용된 뉴스 기사 데이터의 전처리 과정, 그리고 마지막으로 3)MemNN 모델 구현 코드에 대해 차례대로 설명하도록 하겠다. (전체 코드는 깃허브 참조)
[1] 참조 코드 설명 및 응용
참조한 코드는 이 사이트에서 확인할 수 있다. 여기서는 아주 간단한 문장으로 학습을 하는데, 데이터는 다음과 같이 이루어져 있다.
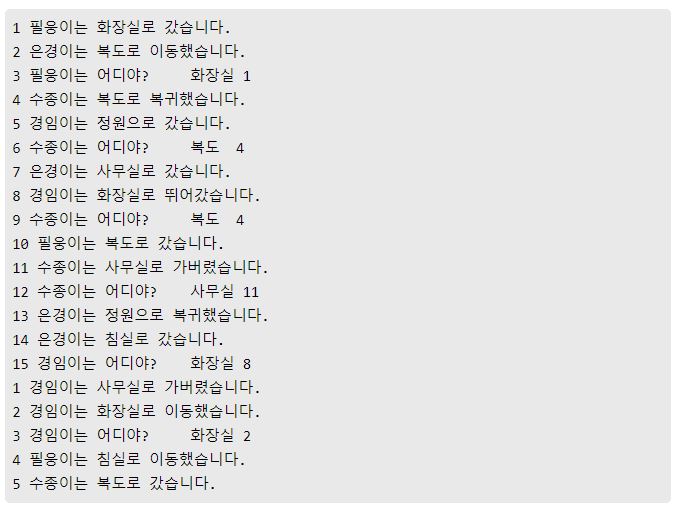
데이터셋을 보면 '필웅이는 화장실로 갔습니다', '은경이는 복도로 이동했습니다'라는 텍스트가 있는데 이를 보고, '필웅이는 어디야?'라는 질문에 '화장실'을 대답하도록 하는 모델을 만든다.
위 데이터셋을 보면 반복되는 사람이름, 장소, 단어가 많고, 그러한 문장들로 학습이 된다. 따라서 그만큼 학습 성능이 좋은 것을 확인할 수 있다. 이제 여기서 MemNN을 사용한 코드를 참고하여 단순 문장이 아닌 뉴스 기사 텍스트를 학습시켜 질의응답 예측을 하는 모델을 만들어보도록 하겠다.
[2] 뉴스 기사 데이터 전처리
학습에 사용할 데이터는 AIHUB에서 다운받은 [기계독해] 분야의 데이터로, 뉴스기사 본문, 질문, 답, 그리고 답이 있는 문장이 하나의 데이터셋으로 있는 json 형식의 데이터이다. 파일을 열어보면 아래와 같은 형식으로 이루어져 있어서 전처리를 해주어야 하고, 참조한 코드의 데이터 형식과 동일하게 해주어야 한다. 한편, 데이터를 다운로드하면 총 3개의 데이터가 있는데 그중 ko_nia_clue0529_squad_all.json 파일을 사용해주었다.
{"data": [{
"source": 6,
"paragraphs": [{
"qas": [{
"question": "쎈 마이웨이 관련 기자간담회 누가 했어",
"id": "m4_278529-1",
"answers":[{
"answer_start": 0,
"text": "박영선"
}],
"clue":[{
"clue_start": 4,
"clue_text": "PD"
}],
"classtype": "work_who"
}],
"context": "박영선 PD는 18일 오후 서울 양천구 목동 SBS에서 모비딕의 토크 콘텐츠 쎈 마이웨이 관련 기자간담회를 열고 출연진에 신뢰를 드러냈다."
}],
"title": “1"
}
그렇다면 이제 전처리 과정의 코드를 설명하도록 하겠다.
(1) 데이터 전처리
먼저 json 파일을 열어야 하기 때문에 json 모듈을 import 해주어야 한다.
import json
with open('ko_nia_clue0529_squad_all.json', 'r', encoding='UTF8') as f :
json_data = json.load(f)
datas = json_data['data']
print(len(datas))
위 코드를 실행하면 34500이 출력되는데, 이는 전체 데이터의 갯수를 의미한다.
그리고 하나의 데이터를 data[0] 와 같은 식으로 인덱스를 입력하고 출력하면 아까 위에서 데이터 형태를 봤듯이 딕셔너리 형태로 이루어져 있는 것을 확인할 수 있다.
이제 여기서 5번째 데이터의 본문, 단서가 되는 문장, 질문, 답만 출력해보겠다.
print(datas[5]['paragraphs'][0]['context'])
print()
print(datas[5]['paragraphs'][0]['qas'][0]['clue'][0]['clue_text'])
print()
print(datas[5]['paragraphs'][0]['qas'][0]['question'])
print(datas[5]['paragraphs'][0]['qas'][0]['answers'][0]['text'])<출력>
파란 출신 시윤 새 싱글 ‘너와 내 사이’ 강민희 피처링, 야마아트 프로듀싱 그룹 ‘파란’ 출신 시윤의
새 싱글앨범 ‘너와 내 사이’가 12일 정오에 공개돼 화제다. 최근 JTBC ‘슈가맨 시즌‘에서 근황을 알린
시윤의 신곡 ‘너와 내 사이’는 권태기를 맞은 연인의 이별 이야기를 그렸다. 몽환적의 분위기와
누구나 한번쯤 겪어봤을 법한 가사에 시윤의 감성적인 보컬을 더해 눈길을 끈다. 싱어송라이터로
홀로 서는 시윤의 색깔을 충분히 느낄 수 있는 앨범. ‘너와 내 사이’는 아이돌리부팅 프로그램
더유닛에서 보컬리스트로 활약한 강민희가 피처링에 참여했음 프로듀싱팀 야마아트도 함께해 완성도를
더했다. 야마아트는 세븐틴, 뉴이스트W 등과 함께 작업한 바 있ㄷ. 한편 ‘너와 내 사이’는 식어버린
감정 그리고 변해버린 말투와 표정에서부터 우리라는 단어가 어느새 어색해지고 너와 내가 되어버린
연인의 사이를 사실적이고 현실감 있게 표현한 가사가 인상적인 것으로 알려졌다. [사진=시윤 앨범 자켓]
최근 JTBC ‘슈가맨 시즌‘에서 근황을 알린 시윤의 신곡 ‘너와 내 사이’는 권태기를 맞은 연인의
이별 이야기를 그렸다.
야마아트 프로듀싱 그룹 ‘파란’ 출신 시윤의 새 싱글앨범은?
너와 내 사이
위 코드를 입력하면 위와 같이 본문 텍스트, 질문에 대해 단서가 되는 문장, 질문, 답변이 출력된다.
만약 여러 개의 데이터를 확인하고 싶다면 아래 코드를 실행하면 된다.
for x in range(0,10) : #구간설정
print(datas[x]['paragraphs'][0]['context']) #원문
print()
for i in range(len(datas[x]['paragraphs'][0]['qas'])) :
print(datas[x]['paragraphs'][0]['qas'][i]['question']) #문제
print(datas[x]['paragraphs'][0]['qas'][i]['answers'][0]['text'])#정답
print(datas[x]['paragraphs'][0]['qas'][0]['clue'][0]['clue_text'])
print()
print('-'*70)
이제 중요한 작업을 해야 하는데, 본문 텍스트는 d_stories 라는 리스트에, 질문은 d_questions, 답에 대한 데이터는 d_answers 라는 리스트에 저장하려고 한다. 여기서 처음엔 뉴스기사 본문 전체를 본문 리스트에 저장하고 학습을 시켰다. 하지만 전체적으로 몇 만개의 데이터에 각 뉴스내용이 달라 출현하는 단어도 너무 다르고, 학습률이 너무 떨어짐을 확인했다. 따라서 본문 텍스트는 질문에 대해 단서가 되는 문장으로 지정하기로 했다. 그렇게 되면 답이 있는 문장만을 학습하기 때문에 학습률이 훨씬 높아지고, 형태소 분석 시에도 훨씬 효율이 좋아질 것으로 판단되었다.
한편, 어떤 데이터를 보면 질문이 없는 데이터도 있어서 제외시켜주어야 한다.
또한 답변 데이터도 문장으로 된 경우와 두 개 이상의 단어로 이루어진 답, 그리고 7자 이상의 답변은 제외하기로 했다. 왜냐하면 답변 단어 자체가 하나의 단어로 인식되어 형태소분석기를 거쳐야 하는데, 글자 수가 많거나 두 개 이상의 단어, 또는 문장은 형태소분석기에 의해 한 단어로 인식이 안될 때가 있기 때문이다.
이러한 것들은 코드를 진행하다 막히는 부분들을 통해 정립된 사항들이다. 그럼 이제 아래 코드를 실행해주어 각 리스트에 적절한 데이터들을 저장해준다.
#원문첫문장, 단서문장, 질문, 답변 저장하기
d_stories = []
d_questions = []
d_answers = []
for i in range(len(datas)) :
if datas[i]['paragraphs'][0]['qas'] :
answer = datas[i]['paragraphs'][0]['qas'][0]['answers'][0]['text']
if answer.isalpha() and len(answer) <= 6 :
stories = []
sentences = datas[i]['paragraphs'][0]['context'].split('.')
stories.append(sentences[0])
stories.append(datas[i]['paragraphs'][0]['qas'][0]['clue'][0]['clue_text'])
d_stories.append(stories)
d_questions.append(datas[i]['paragraphs'][0]['qas'][0]['question'])
d_answers.append(datas[i]['paragraphs'][0]['qas'][0]['answers'][0]['text'])
print(len(d_stories))
print(len(d_questions))
print(len(d_answers))
코드 마지막 줄에 각 데이터의 갯수를 출력시켜보았다. 모두 4914로 출력되었는데 원하는 조건에 맞는 데이터가 4914개라는 것이다. 그럼 원하는 데이터만 저장되었는지 인덱스 2의 데이터를 출력해보았다.
x = 2
print(d_stories[x])
print(d_questions[x])
print(d_answers[x])
<출력>
['그룹 방탄소년단의 제이홉이 데뷔 후 처음으로 믹스테이프를 발표한다',
'제이홉은 3월 2일 자신만의 색을 담은 첫 번째 솔로 믹스테이프를 공개한다.']
방탄소년단 멤버 RM과 슈가에 이어 세 번째로 믹스테이프를 발표하는 멤버는 누구야?
제이홉
코드 실행 결과, 답을 찾을 수 있는 텍스트가 본문 리스트에 저장이 되었고, 3글자로 이루어진 하나의 단어인 데이터가 답변 데이터로 잘 저장되어 있음을 확인할 수 있었다.
이제 이 데이터를 각각 train data, test data로 저장을 해주어야 하는데 train data로는 4000개의 데이터를, 테스트 데이터는 200개로 지정하는데 이때 100개의 단어는 train data에 있는 데이터로 지정해주었다.
x = 4000
y = 3900
z = 4100
#train data
train_stories = d_stories[0:x]
train_questions = d_questions[0:x]
train_answers = d_answers[0:x]
#test data
test_stories = d_stories[y:z]
test_questions = d_questions[y:z]
test_answers = d_answers[y:z]
a = 2
print(test_stories[a])
print()
print(test_questions[a])
print(test_answers[a])
한번 잘 분리가 되었는데 위 코드를 입력해보았다. 위 코드를 입력해보면 아까 위에서 살펴본 형식대로 본문문장, 질문, 답변이 출력될 것이다.
이렇게 잘 분리가 되었으면 본문, 질문, 답이 담긴 종합적인 train data, test data를 만들어준다.
#종합 데이터 만들기 (train / test 각각)
train_data = []
train_data.append(train_stories)
train_data.append(train_questions)
train_data.append(train_answers)
print(len(train_data))
print(len(train_data[0]))
print(len(train_data[1]))
print(len(train_data[2]))
print()
test_data = []
test_data.append(test_stories)
test_data.append(test_questions)
test_data.append(test_answers)
print(len(test_data))
print(len(test_data[0]))
print(len(test_data[1]))
print(len(test_data[2]))
중간중간 데이터의 길이를 출력해보았는데 3,4000,4000,4000, 3,200,200,200 이 출력된다면 잘 실행된 것이다. train data와 test data에 본문텍스트, 질문, 답변 리스트를 저장했으니 3이 출력되는 것이 맞고 각 train data, test data에 데이터가 각각 4000, 200개씩 있으니 4000, 200 으로 출력되는 것이 맞다.
마찬가지로 train data 또는 test data 로 데이터를 확인하고 싶다면 아래와 같이 코드를 입력하면 된다. (출력 생략)
z = 2
print(test_data[0][z])
print(test_data[1][z])
print(test_data[2][z])
(2) 토큰화 함수 정의 및 vocabulary 생성함수 만들기
이제 토큰화 함수를 정의해주는 작업을 해주어야 하는데, 먼저 아래 코드를 입력하여 필요한 모듈을 가져온다.
from ckonlpy.tag import Twitter
from tensorflow.keras.utils import get_file
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import numpy as np
from nltk import FreqDist
from functools import reduce
import os
import re
import matplotlib.pyplot as plt
이때 numpy의 버전을 확인해봐야 하는데 numpy 버전이 1.19.0 이상이면 앞으로의 코드를 실행하지 못한다. 따라서 다운그레이드를 해주어야 하는데 1.18.5로 다운그레이드 하고 진행해주었다. numpy 버전 확인은 아래 코드를 통해 알 수 있다.
import numpy
print(numpy.version.version)
한편, 형태소 분석기는 Twitter를 사용한다. Okt로 이름이 바뀌었지만 Twitter 라는 이름으로도 여전히 사용이 가능하다. 아래 코드를 실행해주도록 한다.
twitter = Twitter()
토큰화를 하기 전에 정답 단어를 단어로 등록해주어야 하므로 아래 코드를 실행해준다.
# 정답 단어 => 단어로 등록해주기
for ans in train_answers :
twitter.add_dictionary(ans, 'Noun')
for ans in test_answers :
twitter.add_dictionary(ans, 'Noun')
그리고 나서 토큰화, 전처리로 지정한 함수를 실행해준다.
def tokenize(sent):
return twitter.morphs(sent)
def preprocess_data(train_data, test_data):
counter = FreqDist()
# 두 문장의 story를 하나의 문장으로 통합하는 함수
flatten = lambda data: reduce(lambda x, y: x + y, data)
# 각 샘플의 길이를 저장하는 리스트
story_len = []
question_len = []
for stories, questions, answers in [train_data, test_data]:
for story in stories:
stories = tokenize(flatten(story)) # 스토리의 문장들을 펼친 후 토큰화
story_len.append(len(stories)) # 각 story의 길이 저장
for word in stories: # 단어 집합에 단어 추가
counter[word] += 1
for question in questions:
question = tokenize(question)
question_len.append(len(question))
for word in question:
counter[word] += 1
for answer in answers:
answer = tokenize(answer)
for word in answer:
counter[word] += 1
# 단어 집합 생성
word2idx = {word : (idx + 1) for idx, (word, _) in enumerate(counter.most_common())}
idx2word = {idx : word for word, idx in word2idx.items()}
# 가장 긴 샘플의 길이
story_max_len = np.max(story_len)
question_max_len = np.max(question_len)
return word2idx, idx2word, story_max_len, question_max_len
word2idx, idx2word, story_max_len, question_max_len = preprocess_data(train_data, test_data)
위 코드를 통해 이제 토큰화가 진행되는데, 약간의 시간이 소요될 것이다. 만약 뉴스기사 본문 전체를 토큰화 했다면 엄청난 시간이 소요될 것이다.
위 코드실행이 끝나고 word3idx 또는 idx2word 를 출력하면 단어와 인덱스 번호가 저장된 딕셔너리가 출력될 것이다.
아래 코드를 실행해주면 단어집의 크기를 확인할 수 있다.
vocab_size = len(word2idx) + 1
print(vocab_size)
그러면 23065가 출력되는데, 약 2만3천개의 단어가 저장된 것이다. 효율적인 학습을 위해 불용어를 제거하고 상위 몇 개의 단어만 사용해도 되는데 이 부분은 넘어가도록 하겠다.
이제 아래 코드를 실행하여 토큰화가 된 단어들을 벡터화하는 과정을 진행해준다.
def vectorize(data, word2idx, story_maxlen, question_maxlen):
Xs, Xq, Y = [], [], []
flatten = lambda data: reduce(lambda x, y: x + y, data)
stories, questions, answers = data
for story, question, answer in zip(stories, questions, answers):
xs = [word2idx[w] for w in tokenize(flatten(story))]
xq = [word2idx[w] for w in tokenize(question)]
Xs.append(xs)
Xq.append(xq)
Y.append(word2idx[answer])
return pad_sequences(Xs, maxlen=story_maxlen),\
pad_sequences(Xq, maxlen=question_maxlen),\
to_categorical(Y, num_classes=len(word2idx) + 1)
Xstrain, Xqtrain, Ytrain = vectorize(train_data, word2idx, story_max_len, question_max_len)
Xstest, Xqtest, Ytest = vectorize(test_data, word2idx, story_max_len, question_max_len)
print(Xstrain.shape, Xqtrain.shape, Ytrain.shape, Xstest.shape, Xqtest.shape, Ytest.shape)
<출력결과>
(4000, 287) (4000, 76) (4000, 23065) (200, 287) (200, 76) (200, 23065)
위 출력결과에서 287은 본문 텍스트의 최대 길이, 76은 질문의 최대 길이를 의미한다.
여기까지 코드 실행을 완료했다면 데이터의 준비가 끝난 것이다!
[3] MemNN 모델 구현
여기서부터는 위에서 언급한 참조 코드와 거의 동일하다.
모델을 빌드업 하기 위해선 텐서플로우의 케라스를 이용한다. 먼저 아래 코드를 실행해준다.
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Embedding
from tensorflow.keras.layers import Permute, dot, add, concatenate
from tensorflow.keras.layers import LSTM, Dense, Dropout, Input, Activation
그리고 에포크, 배치사이즈, 임베딩 사이즈, LSTM 크기, 드롭아웃 값을 아래와 같이 설정하여 지정해준다.
train_epochs = 120
batch_size = 32
embed_size = 50
lstm_size = 64
dropout_rate = 0.30
아래 코드를 실행해주어 데이터를 입력 형태로 만들어 준다.
input_sequence = Input((story_max_len,))
question = Input((question_max_len,))
print('Stories :', input_sequence)
print('Question:', question)<출력>
Stories : Tensor("input_5:0", shape=(None, 287), dtype=float32)
Question: Tensor("input_6:0", shape=(None, 76), dtype=float32)
그러고 나서 각 본문, 질문에 대해 임베딩을 해준다.
#본문
input_encoder_m = Sequential()
input_encoder_m.add(Embedding(input_dim=vocab_size,
output_dim=embed_size))
input_encoder_m.add(Dropout(dropout_rate))
input_encoder_c = Sequential()
input_encoder_c.add(Embedding(input_dim=vocab_size,
output_dim=question_max_len))
input_encoder_c.add(Dropout(dropout_rate))
#질문
question_encoder = Sequential()
question_encoder.add(Embedding(input_dim=vocab_size,
output_dim=embed_size,
input_length=question_max_len))
question_encoder.add(Dropout(dropout_rate))
# 실질적 임베딩 과정
input_encoded_m = input_encoder_m(input_sequence)
input_encoded_c = input_encoder_c(input_sequence)
question_encoded = question_encoder(question)
마지막 작업으로 본문의 단어들과 질문 단어들 간의 유사도를 구한다. 이 부분이 앞부분에서 살펴보았던 MemNN의 4가지 요소들이 반영되는 부분이다.
# 내적을 통한 유사도 구하기
match = dot([input_encoded_m, question_encoded], axes=-1, normalize=False)
match = Activation('softmax')(match)
print('Match shape', match)
response = add([match, input_encoded_c]) # (samples, story_max_len, question_max_len)
response = Permute((2, 1))(response) # (samples, question_max_len, story_max_len)
print('Response shape', response)
answer = concatenate([response, question_encoded])
print('Answer shape', answer)
answer = LSTM(lstm_size)(answer) # Generate tensors of shape 32
answer = Dropout(dropout_rate)(answer)
answer = Dense(vocab_size)(answer) # (samples, vocab_size)
answer = Activation('softmax')(answer)
이제 model을 만들어 학습을 시켜주도록 한다.
model = Model([input_sequence, question], answer)
model.compile(optimizer='rmsprop', loss='categorical_crossentropy',
metrics=['acc'])
print(model.summary())
history = model.fit([Xstrain, Xqtrain],
Ytrain, batch_size, train_epochs,
validation_data=([Xstest, Xqtest], Ytest))
# save model
model.save('model.h5')
위 코드를 실행하면 모델의 정보가 나오고 학습이 시작되는데 약 1시간 가량이 소요되었다. 전체 뉴스기사 본문으로 학습했을 때에는 약 2시간 넘게 소요되었었다.
한편, 참조 코드에 train data와 test data의 정확도와 손실 값을 비교해볼 수 있는 코드가 있어서 실행해보았다.
# plot accuracy and loss plot
plt.subplot(211)
plt.title("Accuracy")
plt.plot(history.history["acc"], color="g", label="train")
plt.plot(history.history["val_acc"], color="b", label="validation")
plt.legend(loc="best")
plt.subplot(212)
plt.title("Loss")
plt.plot(history.history["loss"], color="g", label="train")
plt.plot(history.history["val_loss"], color="b", label="validation")
plt.legend(loc="best")
plt.tight_layout()
plt.show()
# labels
ytest = np.argmax(Ytest, axis=1)
# get predictions
Ytest_ = model.predict([Xstest, Xqtest])
ytest_ = np.argmax(Ytest_, axis=1)
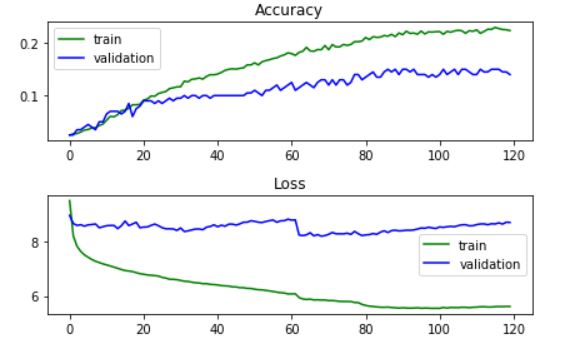
출력된 결과를 보면 train data의 경우 정확도가 점점 올라가고 손실 값은 줄어들었지만 test data의 경우 정확도는 약간씩만 올라가고 손실 값은 줄어드는가 싶더니 어느 수준에 도달하고 움직이지 않았다.
하지만 수치로 보면 학습이 잘 되었는지 가늠하기 어렵기 때문에 test data에 대해 어떻게 답변을 예측했는지 살펴보았다.
for i in range(200):
label = idx2word[ytest[i]]
prediction = idx2word[ytest_[i]]
print(f'{i+1}번')
print('문제 :',test_data[1][i])
print(f'예측 : {prediction}')
print(f'정답 : {label}')
print('='*70)
1번
문제 : 2018 평창 동계올림픽의 개막을 앞두고 어떤 팀을 발족해?
예측 : 독전
정답 : 특별취재팀
======================================================================
2번
문제 : 자격 없이 안마시술소를 개설한 사람은 누구야?
예측 : A씨
정답 : A씨
======================================================================
3번
문제 : 서울시는 7월 3일부터 15일까지 서울도서관에서 무엇을 열어?
예측 : 증가
정답 : 평양책방
======================================================================
4번
문제 : 3,195원에 거래중인 기업이 어디야?
예측 : 세중
정답 : 세중
======================================================================
5번
문제 : KB국민은행이 어떤 혐의로 수사를 받고있어?
예측 : 검찰
정답 : 채용비리
======================================================================
.
.
.
코드를 실행하면 위와 같은 형태로 200개의 test data에 대해 어떠한 답변을 예측했는지 출력된다. 위 결과를 보면 5개의 문제 중 2문제는 정답을 맞혔지만 3문제는 오답이다. 200개의 전체 결과를 보면 이와 같은 확률로 예측을 했음을 살펴볼 수 있다.
|| Result
뉴스 기사 데이터 질의응답 데이터와 MemNN 모델을 이용하여 질의응답 모델을 만들어보았다. 학습 결과 50%에 미치지 못한 정답률을 보였는데, 아무래도 참조한 코드에서 사용한 데이터와는 달리 뉴스 기사 데이터는 각 데이터마다 단어가 너무 달랐고, 비슷한 문장들이 없었다. 따라서 동일한 뉴스 기사를 변형한 문장들도 함께 학습을 시키면 훨씬 더 높은 정확도를 낼 수 있지 않았을까 싶다. 또한 형성한 단어집도 사실 2만 개는 매우 큰 사이즈라 빈도가 낮은 단어를 찾아내 제외해서 질문과 문장 간의 유사도를 찾았다면 더 높은 정확도를 낼 수 있지 않을까 싶다.
그래도 뉴스기사 데이터가 많이 정제되지 않아 있어서 한 문제라도 맞힐 수 있을까 싶었는데 맞춘 문제들이 꽤 있다는 게 대단하기도 하다. 이렇게 MemNN을 이용하여 예측 모델을 구현해보았는데, MemNN의 알고리즘이 한국어에 대해서도 많이 보완되고 잘 응용될 수 있다면 QnA 등 질의응답 서비스에 활발하게 응용될 수 있을 것이라 생각한다.
|| Reference
- https://wikidocs.net/85470
- Memory Networks
- https://reniew.github.io/45/
- https://godongyoung.github.io/%EB%94%A5%EB%9F%AC%EB%8B%9D/2018/03/11/Memory-Networks-paper-review.html
'PROJECT' 카테고리의 다른 글
| [에어] 'KcELECTRA' 로 악성댓글 분류 모델 만들기 (파이썬/Colab) (1) | 2022.01.16 |
|---|---|
| [에어] InceptionV3으로 한국어(한글) 이미지 캡셔닝(Image Captioning) 모델 만들기 (파이썬/Colab) (4) | 2021.08.26 |
| [에어] TextRank 로 크롤링한 뉴스 기사 요약 모델 만들기 (파이썬/Colab) (1) | 2021.07.15 |
| [에어] Transformer 모델로 오피스 챗봇 만들기 (파이썬/Colab) (0) | 2021.06.07 |
| [에어] 7가지 감정의 한국어 대화, 'KOBERT'로 다중 분류 모델 만들기 (파이썬/Colab) (3) | 2021.05.27 |



