에어 프로젝트
#6 InceptionV3으로 한국어(한글) 이미지 캡셔닝(Image Captioning) 모델 만들기

만약 인공지능이 경기장에서 축구를 하고 있는 사람의 이미지를 보고 '사람이 경기장에서 축구를 하고 있습니다' 또는 '경기장, 사람, 축구, 운동'과 같이 관련 단어나 문장을 자동으로 생성해준다면 어떠할까? 이러한 기능이 활성화된다면 시각장애인에게 도움을 줄 수도 있을뿐더러 데이터 검색, 스포츠 중계, 미술 치료 등 정말 많은 분야에서 활용될 수 있을 것이다.
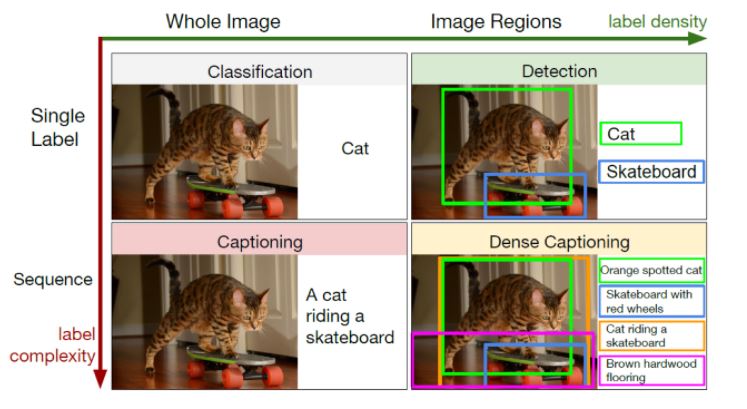
이렇게 인공지능이 이미지를 보고 관련 단어나 문장을 만드는 것을 '이미지 캡셔닝(Image Captioning)' 이라고 하는데, 이 분야는 인공지능의 Text Generation의 한 분야이기도 하다. 또한, 이미지의 특징을 학습한 뒤 하나의 단어 또는 여러 단어를 생성하는 것, 그리고 이전 단어 이후에 나올 단어를 이어서 생성하면서 문장 생성까지, Classification, Detection, Captioning, Dense Captioning으로 나눌 수 있다. 이중에서도 이번 에어프로젝트에서는 이미지를 보고 관련 한국어 단어들을 생성하는 Detection 캡셔닝 모델을 직접 학습시켜 만들고자 한다. 그전에 먼저 캡셔닝에 사용할 모델인 InceptionV3에 대해 알아보도록 하겠다.
|| InceptionV3 이란?
InceptionV3 모델은 구글이 논문(Rethinking the Inception Architecture for Computer Vision)에서 공개한 모델로 2014년 이미지 분류 대회인 IRSVRC에서 1등을 한 모델이다. InceptionV1에서 보완된 모델이 InceptionV2와 InceptionV3인데 V3는 V2 모델에 최적의 기법을 모두 적용해 가장 높은 성능을 나타내는 모델이라고 한다.

InceptionV3은 적은 파라미터를 가지는 42-layer의 신경망인데 위에 표에서 볼 수 있듯이 VGGNet과 비슷한 연산량을 가지지만 보다 적은 에러를 갖는다. 보통 일반적으로 모델의 크기가 증가하면 연산량도 함께 증가하는데, 메모리가 제한되는 환경에서 학습을 하게 되면 그만큼의 성능이 나오지 않게 된다. 이러한 문제를 해결하기 위해 Factorizing Convolutions(합성곱 분해)를 통해 연산량을 최소화하면서 모델의 크기를 키운 것이 바로 InceptionV3인 것이다.
잠깐 Factorizing Convolutions(합성곱 분해)에 대해 알아보자면, 합성곱 분해란 말 그대로 합성곱을 분해시키는 것이다. 아래 그림을 보면 이해하기 쉽다.
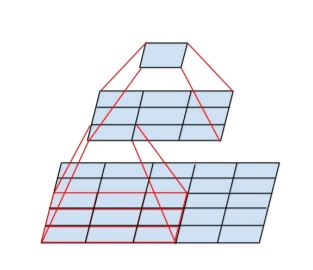
위 그림은 5x5 convolution을 3x3 convolution을 두 개로 분해하는 것을 나타내는데, 5x5 convolution에서 연산은 25번 이루어지는 반면, 두 개의 3x3 convolution에서는 2x3x3=18로 18번의 연산만 이루어진다. 즉, 합성곱 분해를 통해 연산량과 파라미터의 수가 18/25배가 되는 것인데, 이는 모델이 깊어질수록 그 효과가 점점 커지게 된다.
반면, 비대칭 합성곱(Asymmetric Convolutions)이라는 것도 논문에서 제시하는데, 이는 3x3 convolution을 더 작은 convolution으로 분해하는 것이다. 여러 실험 결과, 2x2 convolution이 아닌 비대칭인 nx1 또는 1xn convolution으로 분해하는 것이 더 효과가 좋았다고 한다. 아래 그림은 3x3 convolution을 1x3 convolution으로 분해하는 그림이다. 이렇게 분해를 하면 연산량이 33% 만큼의 절감 효과가 있다고 한다.

그 밖에도 InceptionV3에서는 이미지의 feature map 사이즈를 줄이면서도 신경망의 표현력(representation)을 감소시키지 않는 기법과, 일반화 성능을 높이는 Label Smoothing 기법, 그 밖에도 BN-auxiliary, RMSProp 등을 사용한다. 각 기법에 대한 자세한 내용은 논문을 참고하길 바란다.
|| Project Description
이번 에어 프로젝트에서는 InceptionV3 모델을 이용하여, 주어진 이미지를 보고 관련 한국어(한글) 단어를 예측하는 모델을 만들고자 한다. 프로젝트 모델을 만들기 위해 InceptionV3 모델의 영어 이미지 캡셔닝 예제를 참고했는데, 먼저 1) 학습 이미지 다운 및 전처리에 대해 살펴보고, 영어가 아닌 한글 단어로 캡셔닝을 하기 위한 2) 한국어 단어 임베딩 및 사전 구축 방법, 3)이미지 & 캡션 전처리, 4) 이미지 인코딩 및 InceptionV3 모델 학습, 5) 캡션 생성 모델 학습 및 테스트 순으로 코드를 살펴보도록 하겠다.
[1] 학습 이미지 다운 및 전처리
학습에 사용할 데이터는 AIHUB에서 다운로드한 데이터로, 약 12만 개의 이미지 url과 한국어 문장이 5개씩 포함되어 있는 데이터이다.
예를 들어 아래 이미지의 경우,

1. 빨간 헬멧을 쓴 남자가 작은 오토바이를 타고 비포장 도로에 있다
2. 시골의 비포장 도로에서 오토바이를 타는 남자
3. 오토바이 뒤에 탄 남자
4. 오토바이 위에 젊은이가 탄 비포장 도로는 다리가 있는 초록빛 지역의 전경과 구름 낀 산의 배경이 있다
5. 빨간 셔츠와 빨간 모자를 쓴 남자가 언덕 쪽 오토바이 위에 있다
위와 같이 5개의 문장과 함께 한 세트로 json 형식으로 이루어져 있다. 이 데이터는 AIHUB에서 로그인 후 다운로드 받을 수 있다.
# 1.1 환경 세팅 및 데이터 열기
그렇다면 이제 다운로드 받은 데이터를 구글의 코랩(Colab)에서 열어 이미지를 다운로드 해주어야 한다. 이제 코랩을 열고 코드를 넣어서 실행해보자!
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
위 코드는 나의 구글 드라이브와 연동해주는 코드이다. 실행한 후 출력된 링크로 들어가서 key를 복사해 입력창에 입력해주면 된다. 그리고 여러 파일과 데이터를 저장할 파일경로를 아래와 같이 지정해주면 된다. 뒤에도 중간중간 'data'폴더 등 새로운 폴더를 만들어주어야 하는데, 코드를 보고 해당 폴더를 만들어 주면 된다.
COLAB = True
if COLAB:
root_captioning = "/content/drive/My Drive/이미지캡셔닝" #개인경로
else:
root_captioning = "./data/captions"
AIHUB에서 다운받은 json 파일을 열어서 어떠한 형태로 이루어져 있는지 확인해야 한다.
import json
with open('/content/drive/My Drive/이미지캡셔닝/Korean_caption.json', 'r', encoding='UTF8') as f :
json_data = json.load(f)
print(len(json_data)) #데이터 갯수
# 123287
json_data[0]
# 출력결과
{'caption_ko': ['빨간 헬멧을 쓴 남자가 작은 모터 달린 비포장 도로를 달려 있다.',
'시골의 비포장 도로에서 오토바이를 타는 남자',
'오토바이 뒤에 탄 남자',
'오토바이 위에 젊은이가 탄 비포장 도로는 다리가 있는 초록빛 지역의 전경과 구름 낀 산의 배경이 있다.',
'빨간 셔츠와 빨간 모자를 쓴 남자가 언덕 쪽 오토바이 위에 있다.'],
'captions': ['A man with a red helmet on a small moped on a dirt road. ',
'Man riding a motor bike on a dirt road on the countryside.',
'A man riding on the back of a motorcycle.',
'A dirt path with a young person on a motor bike rests to the foreground of a verdant area with a bridge and a background of cloud-wreathed mountains. ',
'A man in a red shirt and a red hat is on a motorcycle on a hill side.'],
'file_path': 'val2014/COCO_val2014_000000391895.jpg',
'id': 391895}
위 코드와 같이 json파일을 열고 데이터 개수를 확인한 결과 약 12만 개였다. 그리고 첫 번째 데이터를 살펴보면 5개의 문장이 한국어와 영어 버전으로 있는 것을 확인할 수 있다. 또한 그 밑에 'file_path'라는 것이 있는데 이 부분이 바로 이미지의 url 주소 일부이다. 이미지를 다운로드 받기 위해선 이 데이터가 필요하다.
# 1.2 이미지 저장하기
이미지를 저장하기 위해 기본 파일 경로에 'image_caption'이라는 폴더를 만들었고 현재 경로를 여기로 지정해주었다.
os.chdir(r'/content/drive/My Drive/이미지캡셔닝/image_caption')
os.getcwd()
그러고 나서 12만 개의 이미지 중 6000개의 이미지를 저장하기 위한 코드를 실행해준다.
import requests
import urllib.request
import urllib
import os
import time
import tqdm
for i in range(0,6000) :
if i%300 == 0 :
print(i)
try :
img = json_data[i]['file_path'][21:]
url = 'http://images.cocodataset.org/val2014/COCO_val2014_' + img
urllib.request.urlretrieve(url,img)
except :
continue
time.sleep(0.5)
데이터가 많을수록 모델의 성능이 좋아지겠지만 시간상 6000개의 이미지로 설정했다. 컴퓨터 사양이 좋거나 더 좋은 성능을 위해서 값을 조절하면 된다. 이미지 저장은 기본 base url에 위에서 찾은 file_path 주소를 이어 url 주소로 다운로드해주었다. 코드가 다 실행되고 폴더를 학인해보면 6000개의 이미지가 저장된 것을 확인할 수 있을 것이다.
[2] 한국어 단어 임베딩 및 사전 구축
그다음으로는 한국어 캡션을 위한 토큰화, 임베딩 및 사전 구축을 해주어야 한다. 영어 문장의 경우 임베딩을 통해 문장을 생성하는 것이 한국어보다 수월하다. 하지만 한국어의 경우 '은, 는, 이, 가'와 같은 조사, 불용어 등으로 문장을 쪼개서 학습시키는 것 까지는 괜찮아도 다시 문장 생성할 때가 어렵다. 많지 않은 학습량으로는 알맞은 조사가 적절히 연결될 리가 없기 때문에 자연스러운 문장 생성이 어려운 것이다. 따라서 이번 프로젝트도 최종 캡셔닝이 문장 생성이 아닌 단어의 배열인 이유도 여기에 있다.
# 2.1 한국어 캡션 토큰화
아무튼 다시 돌아와서, 먼저 5 문장으로 이루어진 한국어 캡션에 대해 토큰화를 해야 한다. 여기서는 konlpy, Okt 분석기를 사용해주었다. 아래 코드를 통해 모듈을 설치해주자.
!pip install konlpy
from konlpy.tag import Okt
okt=Okt()
okt.morphs()를 통해 토큰화가 이루어지는데, okt.nouns()를 사용하면 명사만 나열된다. 아래는 한국어 캡션에 대해 각각 토큰화한 결과이다.
# 전체 토큰화
for i in json_data[0]['caption_ko'] :
print(okt.morphs(i))
# 출력결과
['빨간', '헬멧', '을', '쓴', '남자', '가', '작은', '모터', '달린', '비', '포장', '도로', '를', '달려', '있다', '.']
['시골', '의', '비', '포장', '도로', '에서', '오토바이', '를', '타는', '남자']
['오토바이', '뒤', '에', '탄', '남자']
['오토바이', '위', '에', '젊은이', '가', '탄', '비', '포장', '도로', '는', '다리', '가', '있는', '초록빛', '지역', '의', '전경', '과', '구름', '낀', '산', '의', '배경', '이', '있다', '.']
['빨간', '셔츠', '와', '빨간', '모자', '를', '쓴', '남자', '가', '언덕', '쪽', '오토바이', '위', '에', '있다', '.']
# 토큰화 - 명사만
for i in json_data[0]['caption_ko'] :
print(okt.nouns(i))
# 출력결과
['헬멧', '남자', '모터', '비', '포장', '도로']
['시골', '비', '포장', '도로', '오토바이', '남자']
['오토바이', '뒤', '남자']
['오토바이', '위', '젊은이', '비', '포장', '도로', '다리', '초록빛', '지역', '전경', '구름', '산', '배경']
['셔츠', '모자', '남자', '언덕', '쪽', '오토바이', '위']
출력 결과를 보면 문장에서 명사만 딱 뽑아서 나열된 것을 확인할 수 있다.
이제 6000개의 데이터에 있는 각 5 문장의 캡션에 대해서 토큰화를 수행해주도록 하겠다.
sent_token = []
for j in range(6000) :
for i in json_data[j]['caption_ko'] :
sent_token.append(okt.nouns(i))
# 2.2 GloVe 한국어 임베딩 사전 만들기
다음 단계로 한국어 임베딩 사전을 만들어 주어야 한다. 한국어 임베딩 사전은 간단하게 말하면 학습할 단어를 숫자로 이루어진 행렬 값을 만들고, 그 단어에 정수를 매칭해 {'사과' : 123, '딸기' : 234} 와 같이 말 그대로 사전을 만드는 작업이다. 이 작업을 위해서 GloVe를 사용해주었다. 먼저 아래 코드를 실행해주자.
!pip install glove_python_binary
from glove import Corpus, Glove
import numpy as np
이때 임베딩을 하기 위한 모델의 파라미터 값을 설정해주어야 하는데, 아래 코드에서 중간에 no_components가 몇 차원으로 할지에 대한 부분이다. 이번 프로젝트에서는 200으로 설정해주었다. 이 부분은 나중에 캡션 생성 모델의 입력 값 차원과도 연결된다.
# corpus 생성
corpus = Corpus()
corpus.fit(sent_token, window=20)
# model
glove = Glove(no_components=200, learning_rate=0.01) # 0.05
%time glove.fit(corpus.matrix, epochs=50, no_threads=4, verbose=False) # Wall time: 8min 32s
glove.add_dictionary(corpus.dictionary)
# save
glove.save('/content'+ '/glove_w20_epoch50.model')
# load glove
glove_model = Glove.load('/content' + '/glove_w20_epoch50.model')
이제 아래 코드를 통해 word dictionary를 생성해준다.
# word dict 생성
import pickle
word_dict = {}
for word in glove_model.dictionary.keys():
word_dict[word] = glove_model.word_vectors[glove_model.dictionary[word]]
print('[Success !] Length of word dict... : ', len(word_dict))
# save word_dict
with open('/content' + '/glove_word_dict_128.pickle', 'wb') as f:
pickle.dump(word_dict, f)
print('[Success !] Save word dict!...')
#출력결과
[Success !] Length of word dict... : 5091
[Success !] Save word dict!...
위에서 하단에 print() 출력 결과 단어집의 크기는 5091 라고 한다. 즉 6000개 X 5문장에 총 5091개의 단어가 있는 것이다. 따로 word_dict를 출력해보면 잘 구축된 것을 확인할 수 있을 것이다.
이제 종합해서 200차원 임베딩 딕셔너리를 만들어준다.
# 200차원 임베딩 딕셔너리
embeddings_index = {}
for i in range(len(word)) :
embeddings = word_dict[word[i]]
coefs = np.asarray(embeddings, dtype='float32')
embeddings_index[word[i]] = coefs
아래 코드를 실행하면 다음과 같이 결과가 출력된다.
print(embeddings_index['헬멧'])
#출력결과
[ 0.0258449 -0.04155635 -0.02331053 0.00657409 -0.03073182 -0.03154416
-0.0261068 0.03759743 -0.02478075 0.03134722 -0.03364773 -0.0006595
0.03101797 0.02920944 0.03491496 -0.03065343 -0.03378497 -0.00872652
.
.
.
0.03393236 0.02652545 -0.01942565 0.01910846 0.03132625 -0.02139902
-0.01911114 0.02551417 -0.00269684 -0.0320207 -0.00031406 0.03394148
0.03107126 -0.0015104 0.03577235 -0.03626085 0.0235488 0.01767512
-0.03971174 -0.03453271]
중간에 값이 생략되었지만 총 200개의 값들이 출력된다.
[3] 이미지 & 캡션 전처리
임베딩 사전을 구축했다면, 이제 모델의 입력값으로 들어갈 이미지와 캡션을 전처리해주어야 한다. 먼저 필요한 모듈을 설치해준다.
import os
import string
import glob
from tensorflow.keras.applications import MobileNet
import tensorflow.keras.applications.mobilenet
from tensorflow.keras.applications.inception_v3 import InceptionV3
import tensorflow.keras.applications.inception_v3
from tqdm import tqdm
import tensorflow.keras.preprocessing.image
import pickle
from time import time
import numpy as np
from PIL import Image
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (LSTM, Embedding,
TimeDistributed, Dense, RepeatVector,
Activation, Flatten, Reshape, concatenate,
Dropout, BatchNormalization)
from tensorflow.keras.optimizers import Adam, RMSprop
from tensorflow.keras import Input, layers
from tensorflow.keras import optimizers
from tensorflow.keras.models import Model
from tensorflow.keras.layers import add
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
def hms_string(sec_elapsed):
h = int(sec_elapsed / (60 * 60))
m = int((sec_elapsed % (60 * 60)) / 60)
s = sec_elapsed % 60
return f"{h}:{m:>02}:{s:>05.2f}"
그리고 캡션 중 최대 길이를 갖는 캡션의 길이를 찾고, 토큰화 된 5개의 문장을 하나의 리스트에 넣어 lookup이라는 딕셔너리에 추가해준다. 한편, 각 이미지에 있는 id가 딕셔너리의 key값이 된다.
null_punct = str.maketrans('', '', string.punctuation)
lookup = dict()
max_length = 0
for i in range(6000) :
id = json_data[i]['file_path'][21:-4] #jpg 파일 이름
descs = []
for desc in json_data[i]['caption_ko'] :
new_desc = okt.nouns(desc)
max_length = max(max_length, len(new_desc))
new_desc = ' '.join(new_desc)
descs.append(new_desc)
lookup[id] = descs
lex = set(word)
print(max_length)
print(len(lookup)) # 총 데이터 갯수
print(lookup['000000391895']) # 1개의 데이터에 5개의 이미지를 가짐 / id(key)는 jpg 파일이름
print(len(lex)) #단어집
#출력결과
25
6000
['헬멧 남자 모터 비 포장 도로', '시골 비 포장 도로 오토바이 남자', '오토바이 뒤 남자', '오토바이 위 젊은이 비 포장 도로 다리 초록빛 지역 전경 구름 산 배경', '셔츠 모자 남자 언덕 쪽 오토바이 위']
3
위에 출력결과에서 세 번째 출력된 lookup 리스트의 형태처럼 만들어 주는 것이 중요하다.
이제 앞에서 다운로드 받은 6000개의 이미지를 train data와 test data로 나눠준다. 이 프로젝트에서는 train data와 test data를 각각 5000개, 1000개로 지정해주었다.
#이미지 파일명 => train / test 나누기
train_img = []
test_img = []
for i in range(6000) :
if i < 5000 :
train_img.append(json_data[i]['file_path'][21:])
else :
test_img.append(json_data[i]['file_path'][21:])
그러고 나서 lookup 딕셔너리에 train data에 해당되는 이미지만 가져와서 다시 딕셔너리에 저장한다. 이때 id값을 이용해서 식별해준다.
#lookup딕셔너리에서 train_images에 있는 데이터만 가져와 다시 딕셔너리로 저장
train_descriptions = {}
cnt = 1
for key, value in lookup.items() :
if cnt > 5000 :
break
desc = []
for v in value :
desc.append(f'startseq {v} endseq')
train_descriptions[key] =desc
cnt += 1
위 코드를 보면 'startseq {v} endseq' 라는 부분이 있다. {v} 부분은 토큰화 된 캡션 부분인데 그 앞 뒤로 startseq와 endseq를 추가해준다. 이 부분은 바로 InceptionV3 모델로 학습시킬 때 문장의 처음과 끝을 나타내는 토큰으로 모델이 인식하도록 한 것이다. 따라서 모든 캡션에 대해 startseq와 endseq라는 토큰을 달아준다.
그렇다면 잘 수행됐는지 확인해보자.
train_descriptions['000000391895']
#출력결과
['startseq 헬멧 남자 모터 비 포장 도로 endseq',
'startseq 시골 비 포장 도로 오토바이 남자 endseq',
'startseq 오토바이 뒤 남자 endseq',
'startseq 오토바이 위 젊은이 비 포장 도로 다리 초록빛 지역 전경 구름 산 배경 endseq',
'startseq 셔츠 모자 남자 언덕 쪽 오토바이 위 endseq']
출력결과, 캡션 앞 뒤로 startseq 토큰과 endseq 토큰이 붙었음을 확인할 수 있다.
이제 train data에 있는 모든 캡션을 하나의 리스트로 저장한다.
#모든 descriptions(=captions)을 리스트로 저장 / 학습할 train data만 진행
all_train_captions = []
for key, val in train_descriptions.items():
for cap in val:
all_train_captions.append(cap)
len(all_train_captions)
# >> 25022
이때 빈도수가 10보다 적은 단어는 제외시키도록 한다. 빈도수가 너무 적은 단어까지 포함시켜 학습을 하게 되면 시간이 많이 소요될 뿐만 아니라 정확도가 낮아질 수 있다.
#빈도수가 10보다 적은 단어는 제외
word_count_threshold = 10
word_counts = {}
nsents = 0
for sent in all_train_captions:
nsents += 1
for w in sent.split(' '):
word_counts[w] = word_counts.get(w, 0) + 1
vocab = [w for w in word_counts if word_counts[w] >= word_count_threshold]
print('preprocessed words %d ==> %d' % (len(word_counts), len(vocab)))
#>> preprocessed words 4758 ==> 1202
위 코드를 실행하면 약 5천 개 가량의 단어가 약 1200개로 줄어들었음을 확인할 수 있다.
이제 각 단어에 대해 인덱스 번호를 부여하는 딕셔너리를 만들어보자.
idxtoword = {} # {인덱스 : 단어}
wordtoidx = {} # {단어 : 인덱스}
ix = 1
for w in vocab:
wordtoidx[w] = ix
idxtoword[ix] = w
ix += 1
vocab_size = len(idxtoword) + 1
max_length +=2 #start 토큰, stop 토큰 때문에 +2
print(max_length)
# >> 27
wordtoidx를 출력하면 다음과 같은 형태의 딕셔너리가 출력된다.
{'startseq': 1,
'헬멧': 2,
'남자': 3,
'모터': 4,
'비': 5,
'포장': 6,
'도로': 7,
'endseq': 8,
'시골': 9,
'오토바이': 10,
...}
[4] 이미지 인코딩 및 InceptionV3 모델 학습
# 4.1 이미지 특징 추출
이제 이미지의 특징을 추출하기 위해 InceptionV3 모델을 불러오도록 하겠다.
USE_INCEPTION = True
if USE_INCEPTION:
encode_model = InceptionV3(weights='imagenet') #InceptionV3 사용
encode_model = Model(encode_model.input, encode_model.layers[-2].output)
WIDTH = 299
HEIGHT = 299
OUTPUT_DIM = 2048 #output : 2048
preprocess_input = \
tensorflow.keras.applications.inception_v3.preprocess_input
else:
encode_model = MobileNet(weights='imagenet',include_top=False)
WIDTH = 224
HEIGHT = 224
OUTPUT_DIM = 50176
preprocess_input = tensorflow.keras.applications.mobilenet.preprocess_input
아래 코드를 통해 모델의 정보를 알 수 있다. 출력 결과는 지면상 생략하겠다.
encode_model.summary()
이제 학습을 하기 위한 이미지를 전처리해주고 파라미터 값을 지정한다.
#이미지 인코딩 함수만들기
def encodeImage(img):
# 이미지 사이즈를 표준크기로 재조정
img = img.resize((WIDTH, HEIGHT), Image.ANTIALIAS)
# PIL 이미지를 numpy array로 변경
x = tensorflow.keras.preprocessing.image.img_to_array(img)
# 2D array로 확장
x = np.expand_dims(x, axis=0)
# InceptionV3의 인풋을 위한 전처리
x = preprocess_input(x)
# 인코딩 벡터 반환
x = encode_model.predict(x)
# LSTM을 입력을 위한 shape 조정
x = np.reshape(x, OUTPUT_DIM )
return x
준비가 다 되었다면 아래 코드를 통해 이미지의 feature를 추출한다.
#이미지 인코딩 <= feature 추출
train_path = os.path.join(root_captioning,"koreandata",f'train{OUTPUT_DIM}.pkl')
if not os.path.exists(train_path):
start = time()
encoding_train = {}
for id in tqdm(train_img):
image_path = os.path.join(root_captioning,'image_caption', id)
img = tensorflow.keras.preprocessing.image.load_img(image_path, \
target_size=(HEIGHT, WIDTH))
encoding_train[id] = encodeImage(img)
with open(train_path, "wb") as fp:
pickle.dump(encoding_train, fp)
print(f"\nGenerating training set took: {hms_string(time()-start)}")
else:
with open(train_path, "rb") as fp:
encoding_train = pickle.load(fp)
코랩에서 일반적인 CPU를 사용한 결과 5000개의 데이터에 대해 약 45분이 소요되었다.
마찬가지로 test data에 대해서도 똑같이 진행해준다.
#test data에 대해서도 똑같이 진행
test_path = os.path.join(root_captioning,"koreandata",f'test{OUTPUT_DIM}.pkl')
if not os.path.exists(test_path):
start = time()
encoding_test = {}
for id in tqdm(test_img):
image_path = os.path.join(root_captioning,'image_caption', id)
img = tensorflow.keras.preprocessing.image.load_img(image_path, \
target_size=(HEIGHT, WIDTH))
encoding_test[id] = encodeImage(img)
with open(test_path, "wb") as fp:
pickle.dump(encoding_test, fp)
print(f"\nGenerating testing set took: {hms_string(time()-start)}")
else:
with open(test_path, "rb") as fp:
encoding_test = pickle.load(fp)
# 4.2 데이터 생성
이미지 특징 추출이 완료되었다면 이제 이를 캡션 데이터와 합쳐 하나의 데이터로 만들어주어야 한다. 아래 코드를 통해 데이터 생성 함수를 만들어 준다.
#데이터 생성 함수
def data_generator(descriptions, photos, wordtoidx, \
max_length, num_photos_per_batch):
x1, x2, y = [], [], []
n=0
while True:
for key, desc_list in descriptions.items():
n+=1
photo = photos[key+'.jpg']
# 5 descriptions
for desc in desc_list:
# 각 단어를 시퀀스 리스트 형태로 변환
seq = [wordtoidx[word] for word in desc.split(' ') \
if word in wordtoidx]
# 시퀀스 조합(1개단어, 2개단어,,,)별로 저장
for i in range(1, len(seq)):
in_seq, out_seq = seq[:i], seq[i]
in_seq = pad_sequences([in_seq], maxlen=max_length)[0]
out_seq = to_categorical([out_seq], num_classes=vocab_size)[0]
x1.append(photo)
x2.append(in_seq)
y.append(out_seq)
if n==num_photos_per_batch:
yield ([np.array(x1), np.array(x2)], np.array(y))
x1, x2, y = [], [], []
n=0
[5] 캡션 생성 모델 학습 및 테스트
# 5.1 Neural Network 생성
다음 단계로 캡셔닝을 위한 Neural Network를 생성한다.
#GloVe로부터 embedding matrix 구축 => weight matrix로 사용
embedding_dim = 200 #임베딩차원 = 200(=>features)
embedding_matrix = np.zeros((vocab_size, embedding_dim))
for word, i in wordtoidx.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
embedding_matrix.shape
# >> (1203, 200)
#프리파라미터값 조정
inputs1 = Input(shape=(OUTPUT_DIM,))
fe1 = Dropout(0.5)(inputs1)
fe2 = Dense(256, activation='relu')(fe1)
inputs2 = Input(shape=(max_length,))
se1 = Embedding(vocab_size, embedding_dim, mask_zero=True)(inputs2)
se2 = Dropout(0.5)(se1)
se3 = LSTM(256)(se2)
decoder1 = add([fe2, se3])
decoder2 = Dense(256, activation='relu')(decoder1)
outputs = Dense(vocab_size, activation='softmax')(decoder2)
caption_model = Model(inputs=[inputs1, inputs2], outputs=outputs)
caption_model.summary()
caption_model.layers[2].set_weights([embedding_matrix])
caption_model.layers[2].trainable = False
caption_model.compile(loss='categorical_crossentropy', optimizer='adam')
# 5.2 모델 학습시키기
이제 모델을 학습시킨다.
number_pics_per_bath = 3
steps = len(train_descriptions)//number_pics_per_bath
EPOCHS = 10
model_path = os.path.join(root_captioning,"koreandata",f'caption-model.hdf5')
if not os.path.exists(model_path):
for i in tqdm(range(EPOCHS*2)):
generator = data_generator(train_descriptions, encoding_train,
wordtoidx, max_length, number_pics_per_bath)
caption_model.fit_generator(generator, epochs=1,
steps_per_epoch=steps, verbose=1)
caption_model.optimizer.lr = 1e-4
number_pics_per_bath = 6
steps = len(train_descriptions)//number_pics_per_bath
for i in range(EPOCHS):
generator = data_generator(train_descriptions, encoding_train,
wordtoidx, max_length, number_pics_per_bath)
caption_model.fit_generator(generator, epochs=1,
steps_per_epoch=steps, verbose=1)
caption_model.save_weights(model_path)
print(f"\Training took: {hms_string(time()-start)}")
else:
caption_model.load_weights(model_path)
위에 코드를 실행하면 이제 학습이 이루어지는데, 약 3시간이 소요되었다. 마지막 epoch에서 train data의 최종 에러 값은 3.28, test data의 최종 에러 값은 3.22로 비슷하게 측정되었다.
# 5.3 모델 평가하기
학습이 끝났다면 이미지를 넣어 모델을 평가해주어야 하는데, 마찬가지로 startseq, endseq 토큰 추가 등 전처리를 해주어야 한다.
#캡셔닝 함수 만들기
START = "startseq"
STOP = "endseq"
def generateCaption(photo):
in_text = START
for i in range(max_length):
sequence = [wordtoidx[w] for w in in_text.split() if w in wordtoidx]
sequence = pad_sequences([sequence], maxlen=max_length)
yhat = caption_model.predict([photo,sequence], verbose=0)
yhat = np.argmax(yhat)
word = idxtoword[yhat]
in_text += ' ' + word
if word == STOP:
break
final = in_text.split()
final = final[1:-1]
final = ' '.join(final)
return final
이제 test data 1000개에서 30개만 랜덤으로 뽑아 어떠한 캡션을 생성하는지 확인해보도록 하겠다.
#test data 캡셔닝 확인
import random
for i in range(30): # set higher to see more examples
z = random.randint(0,1000)
pic = list(encoding_test.keys())[z]
image = encoding_test[pic].reshape((1,OUTPUT_DIM))
print(os.path.join(root_captioning,'image_caption', pic))
x=plt.imread(os.path.join(root_captioning,'image_caption', pic))
plt.imshow(x)
plt.show()
print("Caption:",generateCaption(image))
print("_____________________________________")
이미지에 따라 출력된 한국어 캡션 단어는 다음과 같다.








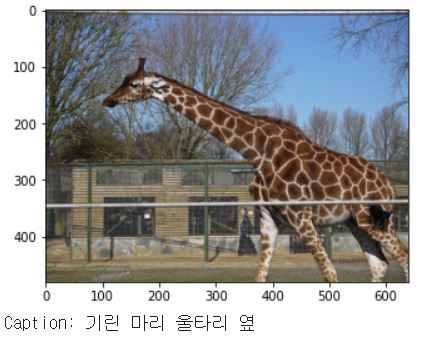

위 결과는 출력된 30개 결과 중 일부이다. 결과를 보면 이미지에 대한 관련 단어가 생각보다 잘 생성된 것을 확인할 수 있다. 맨 마지막 줄에 생성된 캡션이 단어가 아닌 문장으로 출력되도록 모델을 만들었다면 아마 '기린 1마리가 울타리 옆에 있다'라고 출력되지 않았을까 싶다.
한편, test image가 아무래도 train image와 결이 비슷한 이미지일 수 있어서 정확도가 높게 나왔다고 추측할 수 있는데, 이번에는 다른 사진으로 test를 해보았다.
#다른 사진으로 test 해보기
from PIL import Image, ImageFile
from matplotlib.pyplot import imshow
import requests
from io import BytesIO
import numpy as np
%matplotlib inline
def predict(filename) :
image = Image.open('/content/drive/My Drive/파이썬공부/이미지캡셔닝/' + filename)
image.load()
plt.imshow(image)
plt.show()
#예측
image2 = encodeImage(image).reshape((1,OUTPUT_DIM))
print(image2.shape)
print("Caption:",generateCaption(image2))
위 코드에서 predict() 함수는 파일 이름을 넣어주면 캡션이 출력되는 함수로, predict('dog.jpg')와 같이 입력해주면 된다.
그렇다면 다른 이미지에 대해서 어떠한 결과가 나왔는지 살펴보자.


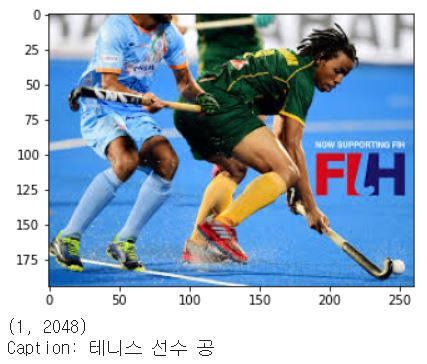





위 이미지 말고도 다른 이미지에 대해서도 테스트를 해봤는데, 위에 결과를 보면 알겠듯이 출력된 캡션을 보면 종류는 비슷하지만 관련없는 단어가 생성되기도 하는 것 같다. 예를 들어, 운동하는 사진들은 종류가 다양해도 스케이트 보드, 테니스, 야구와 같이 한정된 단어로만 출력되었다. 위에서도 달리기가 스케이트 보드로, 필드하키가 테니스로 생성되었다. 이러한 점으로 보아 아마 train data에서 한정적인 몇 개의 운동 이미지만 학습했기 때문에 이러한 결과가 출력되지 않았나 싶다. 만약 12만 개의 이미지를 다 학습시켰다면 그 정확도가 분명 올라갈 것이다.
이렇게 데이터 다운로드부터 시작해서 전처리, InceptionV3 모델, 한국어 임베딩을 거쳐 한국어 캡션 생성까지 해봤는데, 생각보다 학습이 잘 된 것 같고 그 결과가 만족스럽다. 다만 아쉬운 점이 있다면 영어의 경우 문장 생성까지 할 수 있지만 한국어는 문장 생성이 어렵다는 것이다. 하지만 만약 생성된 한국어 단어들을 이용해서 문장을 만들어 주는 모델까지 이어서 만들어준다면 한국어 문장으로 이루어진 캡션 생성이 가능하지 않을까 싶다. 이렇게 좀 더 한국어 캡셔닝 기술이 발전되어 다양한 곳에서 상용화될 수 있다면 참 긍정적인 영향을 가져오지 않을까 싶다.
|| Reference
- 참고 예제
- 참고 예제 도움
- CONNECTING IMAGES AND NATURAL LANGUAGE
- Rethinking the Inception Architecture for Computer Vision
- GloVe 관련 글
- AIHUB 기계독해
- https://deep-learning-study.tistory.com/517
'PROJECT' 카테고리의 다른 글
| [에어] 'KcELECTRA' 로 악성댓글 분류 모델 만들기 (파이썬/Colab) (1) | 2022.01.16 |
|---|---|
| [에어] Memory Networks (MemNN) 로 뉴스 기사 QnA(질의응답) 예측 모델 만들기 (파이썬/Colab) (0) | 2021.08.04 |
| [에어] TextRank 로 크롤링한 뉴스 기사 요약 모델 만들기 (파이썬/Colab) (1) | 2021.07.15 |
| [에어] Transformer 모델로 오피스 챗봇 만들기 (파이썬/Colab) (0) | 2021.06.07 |
| [에어] 7가지 감정의 한국어 대화, 'KOBERT'로 다중 분류 모델 만들기 (파이썬/Colab) (3) | 2021.05.27 |



