[데이터 분석] 빈 데이터 프레임(dataframe) 만드는 방법
pandas 라이브러리로 데이터프레임을 만들 수 있는데요, 기존의 데이터를 이용하여 데이터프레임으로 나타내는 방법과, 처음부터 빈 데이터프레임을 만들어서 데이터를 추가하는 방식으로 만들 수 있습니다. 이번 글에서는 빈 데이터프레임을 만드는 방법에 대해서 살펴보도록 하겠습니다. 1. 빈 데이터프레임 만들기 데이터 프레임을 만드는 방법은 간단한데요, pd.DataFrame() 함수 안에 인덱스 설정과 칼럼의 이름을 지정해주면 됩니다. 예를 들어, 10개의 행과 'A', 'B', 'C' 라는 칼럼을 가진 데이터프레임 'df' 를 만들어보도록 하겠습니다. import pandas as pd df = pd.DataFrame(index=range(0,10),columns=['A','B','C']) 위와 같이 ind..
더보기
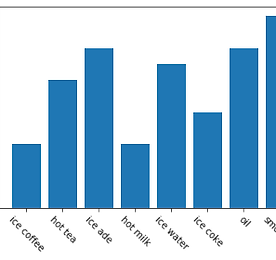 [데이터분석] matplotlib 그래프 : x축 텍스트 회전하는 방법 - rotation
matplotlib 라이브러리는 그래프를 쉽고 간편하게 그릴 수 있도록 도와주는 라이브러리입니다. matplotlib에서는 그래프를 다양하게 그릴 수 있도록 여러 모듈을 제공하는데요, 그중 x축 텍스트를 회전하는 방법에 대해서 살펴보도록 하겠습니다. 먼저, 아래와 같이 간단한 그래프를 그려보도록 하겠습니다. import matplotlib.pyplot as plt import numpy as np x = np.arange(8) item = ['ice coffee', 'hot tea', 'ice ade', 'hot milk', 'ice water', 'ice coke', 'oil', 'smoothie'] values = [2000, 4000, 5000, 2000, 4500, 3000, 5000, 6000]..
더보기
[데이터분석] matplotlib 그래프 : x축 텍스트 회전하는 방법 - rotation
matplotlib 라이브러리는 그래프를 쉽고 간편하게 그릴 수 있도록 도와주는 라이브러리입니다. matplotlib에서는 그래프를 다양하게 그릴 수 있도록 여러 모듈을 제공하는데요, 그중 x축 텍스트를 회전하는 방법에 대해서 살펴보도록 하겠습니다. 먼저, 아래와 같이 간단한 그래프를 그려보도록 하겠습니다. import matplotlib.pyplot as plt import numpy as np x = np.arange(8) item = ['ice coffee', 'hot tea', 'ice ade', 'hot milk', 'ice water', 'ice coke', 'oil', 'smoothie'] values = [2000, 4000, 5000, 2000, 4500, 3000, 5000, 6000]..
더보기

